创智联合华为打造新一代强化学习框架siiRL, 首次实现昇腾千卡集群高效扩展
上海创智学院AIInfra团队于2025年9月份发布siiRL框架2.0版本。框架设计从根本上进行了架构革新,实现了彻底的全分布式设计与多控制器范式。上海创智学院联合华为,完成了siiRL框架与昇腾的适配,实现了从32卡到1024卡的稳定扩展,框架使用FSDP/MindSpeed训练后端,实现了超过90%的线性扩展效率。
大规模强化学习(RL)是当前通往更高阶AI能力的关键技术之一,但其发展一直受限于主流框架在底层架构上的瓶颈。当训练规模扩展至成百上千的计算节点时,传统框架的性能往往会急剧下降,其根源在于其固有的“中心化”设计。
多数主流RL框架依赖中心化的控制器进行数据调度与分发。在这种设计下,所有数据流都必须经过该中心节点,使其在规模扩大时,因巨大的I/O和通信开销成为系统瓶颈,并可能因内存溢出导致训练崩溃。
为彻底解决此问题,上海创智学院AIInfra团队发布的siiRL框架从根本上进行了架构革新,其核心是彻底的全分布式设计与多控制器范式。siiRL移除了中心瓶颈,将数据调度与计算任务均匀地分布到每一个独立的工作单元中。
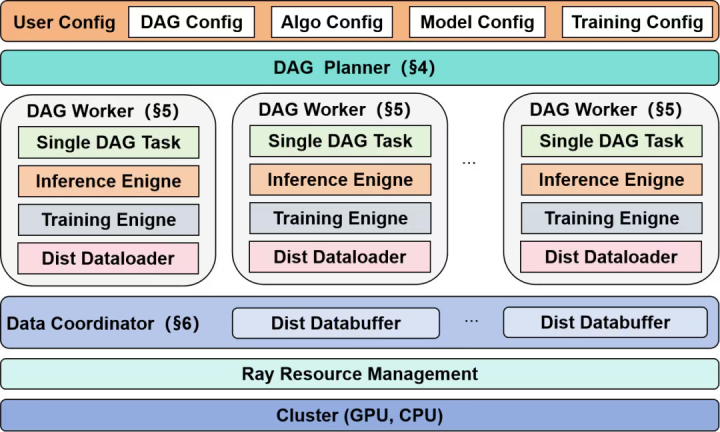
图1:siiRL架构概览
这一创新架构主要由以下三大核心组件构成:
DAGPlanner(规划器):siiRL支持开发者将复杂的RL算法逻辑定义为一个灵活的有向无环图(DAG)。这种设计为算法的迭代与创新提供了极大的灵活性。
DAGWorker(工作单元):每个工作单元绑定一个物理计算设备,独立执行规划器分配的任务。数据在初始阶段就通过分布式加载器被并行载入,避免了源头瓶颈。
DataCoordinator(数据协调器):它确保数据在节点间进行高效的点对点流转。当并行策略变化时,其分布式DataBuffer能自动完成跨节点的数据重组与分发,彻底取代了中心化的数据汇聚模式。
通过这一全新的全分布式架构,siiRL不仅从根本上解决了主流架构的扩展性难题,实现了千卡规模下的近线性扩展,更通过其灵活的DAG工作流,为未来更复杂的多智能体系统等前沿研究铺平了道路。
昇腾适配:首个实现强化学习千卡集群高效扩展
siiRL的全分布式架构在设计上解决了传统强化学习框架的扩展性瓶颈。上海创智学院与华为联合,共同完成了siiRL框架与昇腾的适配。这一过程针对硬件在底层计算、内存管理及通信等方面的特性差异,进行系统性的工程调优。
为了充分发挥昇腾NPU相关能力,双方的优化工作从计算、内存、通信三个维度系统性地展开:
01
计算层深度优化
在计算密集的核心算子层方面,针对昇腾高算力的特性,使用了昇腾优化的rotary_pos_emb、rmsnorm等关键高性能算子,并在ROLLOUT阶段引入了vllm-ascend前沿框架的优化。通过对计算图的精细调优,确保了上层算法逻辑能高效地运行在NPU硬件之上。
02
内存与显存的精细化管理
在显存和内存的使用和管理上,团队进行了一系列精细化配置,例如通过enable_gradient_checkpointing开启梯度重计算,利用use_remove_padding优化数据填充,并调整gpu_memory_utilization等内存分配策略。这些优化使siiRL能在保证显存不溢出的前提下最大化数据吞吐量,将宝贵的显存资源更高效地利用于计算任务。
03
面向硬件拓扑的分布式策略调优
siiRL灵活的架构允许为不同模型定制分布式策略。结合昇腾集群的物理拓扑结构,精心设计了张量切分方式,并调整了进程的亲和性(Affinity)配置,以最大化节点间的通信效率,减少数据传输等待,这在大规模集群中对整体性能至关重要。
通过上述优化,siiRL框架在昇腾集群上实现了从32卡到1024卡的稳定扩展,框架使用FSDP训练后端,实现了超过90%的线性扩展效率。在模型精度上,与benchmark训练结果相比,昇腾集群在验证集上的平均绝对误差控制在0.5%以内,满足实际应用场景的精度要求。此项工作在国内首次完成了强化学习在昇腾千卡集群上的规模化验证与应用。
展示了从32到1024NPU规模下的高线性扩展能力。
从黑盒到透明:Profiling带来的可观测性与加速
在大规模强化学习(RL)场景中,系统由众多模块协同运行:Actor、Rollout、Ref、Critic等环节既相互独立又紧密耦合。性能瓶颈可能隐藏在任意一个模块中,单一维度的观测远远不够。昇腾MindStudio提供的Profiling特性可有效帮助定位性能瓶颈,siiRL框架率先支持NPUProfiling功能,为复杂的训练交互场景提供了良好的可观测性:
模块化采集:开发者可根据需求,选择性地对Actor、Rollout、Ref或Critic等模块进行性能信息采集,避免无关数据干扰,聚焦真正关键的性能瓶颈。
全链路可视化:采集到的数据不仅可以通过昇腾官方工具MindStudioInsight进行硬件级的性能与内存剖析,还可以通过ChromeTrace等通用工具进行时间线可视化分析。
精准诊断与优化:Profiling功能可以采集CPU、NPU及HCCL(华为集合通信库)的性能数据。无论是通信延迟、算子执行效率,还是内存带宽利用率,Profiling都能帮助开发者快速定位瓶颈,为系统优化提供清晰的指引。
持续加速闭环:通过模块级Profiling与工具链的深度结合,开发者可以在RL的复杂任务流中实现从发现问题到优化落地的高效闭环。
从黑盒到透明,Profiling让RL不再是“性能迷宫”。开发者不仅能看到全局运行态势,还能聚焦关键模块,精准释放NPU的算力潜能,加速智能的落地进程。
算力释放
SiiRL与MindSpeedCore的深度融合
为了进一步提升大规模训练效率,siiRL框架已成功完成与MindSpeedCore的对接,大幅增强了基于昇腾的强化学习集群的算力利用率与精度表现。MindSpeedCore是面向昇腾设备推出的亲和加速模块,针对大规模训练任务在融合算子、框架调度等多个层面进行了系统性优化。在siiRL中,仅需通过MindSpeedCore提供的接口进行少量代码改动,即可顺利完成框架适配,使NPU千卡集群能够更高效地运行复杂RL算法。
在测试过程中,充分利用了MindSpeedCore提供的FlashAttentionVarLen、Vector融合算子、FFN层计算合并等核心能力,有效提升了actor训练阶段的算力利用率。得益于此,siiRL框架在NPU集群上实现了从32卡扩展至1024卡规模下超过95%的线性扩展效率。相较于同等规模下采用FSDP后端的方案,其吞吐量最高提升22%,峰值内存占用最高降低20%。
图3:siiRL在昇腾卡使用MindSpeed训练Qwen-7B的扩展性评估,展示了从32到1024NPU规模下的高线性扩展能力。
快速上手
仓库拉取
仓库地址:
https://github.com/sii-research/siiRL
gitclonehttps://github.com/sii-research/siiRL
环境搭建
CANN版本:8.1rc1
torch和torch_npu版本:2.5.1
cdsiiRLcondacreate-ntestpython=3.12pipinstall-rrequirements.txttorch_npu==2.5.1torch==2.5.1#或者前往https://gitee.com/ascend/pytorch/releases/tag/v7.1.0.2-pytorch2.5.1下载torch_npusource/usr/local/Ascend/ascend-toolkit/set_env.shpipinstall-e.
模型权重和数据集下载
使用Qwen2.5-7b模型和DeepScaler数据集作为示例。
模型链接:
https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct
数据集链接:
https://modelscope.cn/datasets/agentica-org/DeepScaleR-Preview-Dataset
用户需要将数据集转换成如下格式:
deepscaler/├──test.parquet└──train.parquet
执行训练
以单机8卡进行演示fsdp后端+profiling功能。
示例代码见链接:
https://github.com/sii-research/siiRL/blob/main/examples/grpo_trainer/run_qwen2_5-7b-npu-e2e_prof.sh
TRAIN_DATA_PATH,TEST_DATA_PATH和MODEL_PATH分别指向训练集、验证集和模型路径,HOME变量可以作为三者的根目录进行设置
#run_qwen2_5-7b-npu-e2e_prof.sh文件部分内容#---PathDefinitions---exportHOME={your_home_path}exportTRAIN_DATA_PATH=$HOME/data/datasets/$DATASET/train.parquetexportTEST_DATA_PATH=$HOME/data/datasets/$DATASET/test.parquetexportMODEL_PATH=$HOME/data/models/Qwen2.5-7B-Instruct