哈佛新论文揭示 Transformer 模型与人脑“同步纠结”全过程!AI也会犹豫、反悔?
原创 文摘菌 大数据文摘

大数据文摘出品
近日,来自哈佛大学、布朗大学以及图宾根大学研究者们,共同发表了一项关于Transformer模型与人类认知处理相关性的研究论文:
——《Linking forward-pass dynamics in Transformers and real-time human processing》
意译过来就是:Transformer模型的“思考过程”与人类大脑实时认知的奇妙相似

换句话说,它想搞清楚一个“老问题”:AI模型的内部处理过程,和人类大脑的实时认知,有多少相似?
过去我们研究AI和人类的相似性,最常见的做法是什么?“看结果”:让AI做题,看它答对多少,概率分布和人的选择对不对得上。例如,让GPT写作文、识别图片、做逻辑推理,然后对照人类的数据,得出一个“AI越来越像人了”的结论。
但这其实只是表象。
想象一个场景:在答一道不太确定的选择题,先想到了一个看似正确的选项,但又觉得不太对,犹豫半天,才最终敲定答案。AI模型也一样,也许在中间某一层,更倾向于一个“直觉答案”,但再往后,才被训练出来的知识“纠正”了过来。
问题来了:AI和人类,不只是最后的选项,连中间的“挣扎”和“转变”也能被对齐吗?
这篇论文的作者,换了个角度:不只看AI模型的输出,还要扒一扒Transformer每一层的“处理动态”,与人脑处理信息的“实时轨迹”是否能对上。
01 AI和人脑,真的在“想”同一件事吗?
图注:方法概述。用Transformer模型中得出的过程性指标预测人类处理负荷和行为反应指标的能力。
论文作者把Transformer每一层的输出和变化都做了记录,提出了一系列“处理负载”的指标:
不确定性(entropy)
信心(log probability)
相对信心(正确vs直觉答案)
boosting(模型在某一层对正确答案的主动“拉高”)
这些东西听起来很技术,但可以简单理解为:AI每一层都在“思考”,每过一层,它对答案的信心发生了一点点变化。
有的题,AI一上来就很有把握,信心很快升高;有的题,AI在中间反复徘徊,甚至先押错,再修正。
这和我们人类做题的“熟练-犹豫-反应慢-反悔-最终确定”是不是很像?
02 实验结果:AI和人类“走弯路”的相似瞬间

图注:研究中分析的人类任务示意图。(a) 回忆(自由回答)首都名称。(b) 识别(强制选择)首都名称。(c) 通过鼠标移动对典型和非典型动物实例进行分类(Kieslich 等, 2020)。(d) 判断三段论推理的逻辑有效性。(e) 对分布外图像进行物体识别。
论文做了几个个实验,分别对应不同的认知任务和人机对比:
①“首都杀手题”——AI和人类的集体下意识。
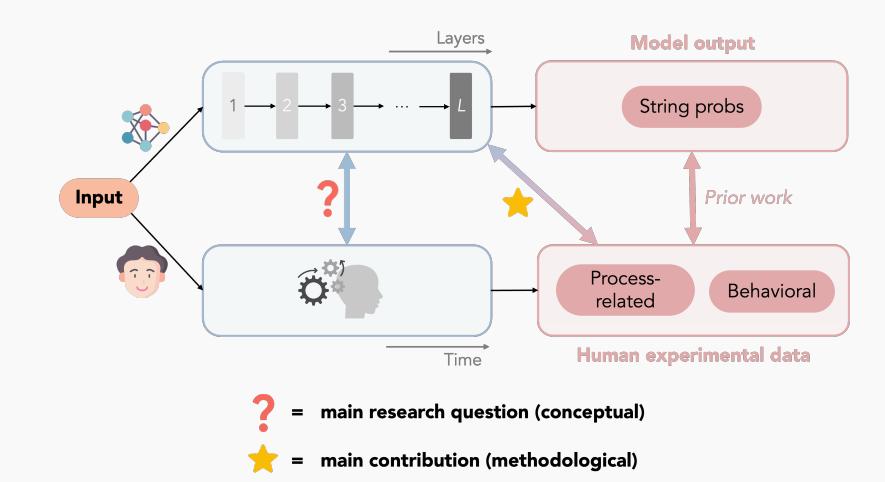
图注:研究1a(回忆首都),Llama-2 7B模型。(a)-(d) 基于模型各层计算的处理指标。(e) 各指标相较于基线模型的BIC差异。数值越高越好。星号表示统计显著。
比如,美国州首都题。这题在答题界有个绰号,叫“首都杀手”:
出题人问:“伊利诺伊州的首都是哪?”
人类几乎下意识地想说:“芝加哥!”
然后突然一个激灵,想起,“不对,是斯普林菲尔德!”
以为这样的“反转”只有人类会有?其实AI也会!
论文里的Llama-2模型,每一层都像个小AI脑细胞在投票。结果显示:在模型的中间层,AI的信心值一度“押宝”在芝加哥上,就像脑海里那个脱口而出的错误答案。可到了后半程,随着层数加深,AI忽然“刹车”,把信心转回了斯普林菲尔德。这就是AI和人类都在“下意识→反思→修正”的本能流程里打了个滚。
更绝的是,有的试题AI和人类都“执迷不悟”。比如问“澳大利亚首都”,一堆人写悉尼,一堆AI也把概率压在悉尼上,最后才有一部分“觉醒”,想起是堪培拉。
②“鲸鱼归属”——鼠标和神经元一起漂移
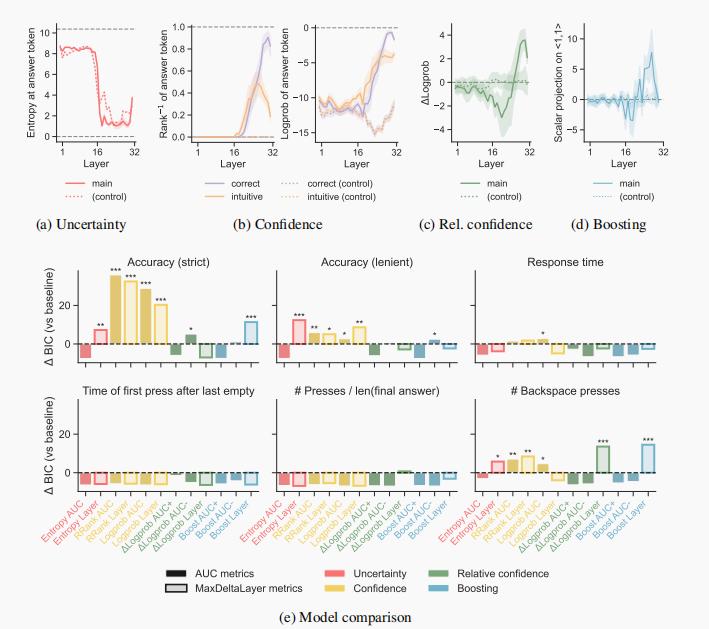
图注:研究2(动物实例分类),Llama-2 7B模型。(a)-(d) 基于模型各层计算的处理指标。(e) 各指标与基线模型的BIC差异,数值越高越好。星号表示统计显著。
再看动物分类题。问:“鲸鱼是鱼还是哺乳动物?”人类是不是脑子里先蹦出来“鱼”,又觉得哪里不对,才慢慢改口?
人类实验里,受试者的鼠标先朝“鱼”方向飘过去,走了一小段“弯路”,再折回“哺乳动物”,画出一条漂亮的“纠结弧线”。
AI模型内部,“信心”指标在前几层也更偏向“鱼”,直到后面层数才被训练出的知识拉回“哺乳动物”。
有趣的是,AI和人类不仅选项重合,连“走神”的路径也同步:人类在鼠标上徘徊的那一秒,AI在网络里也“犹豫”着。
03. “逻辑陷阱”——AI和人类被套路的瞬间
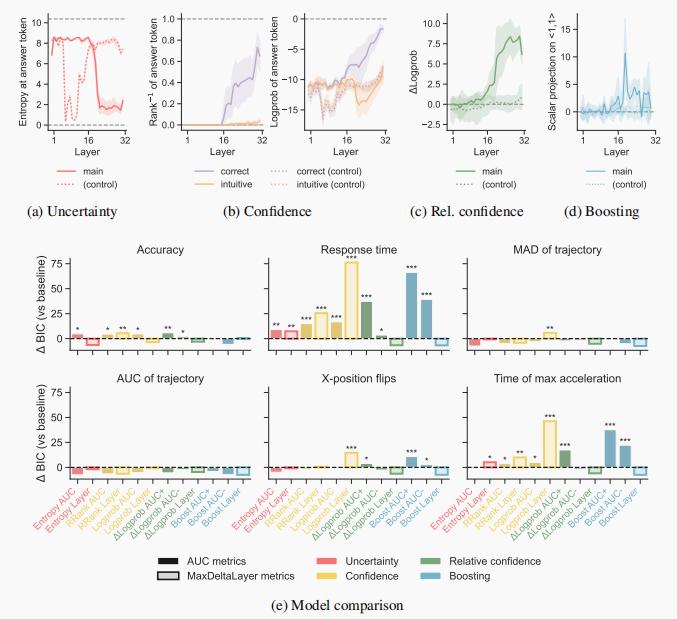
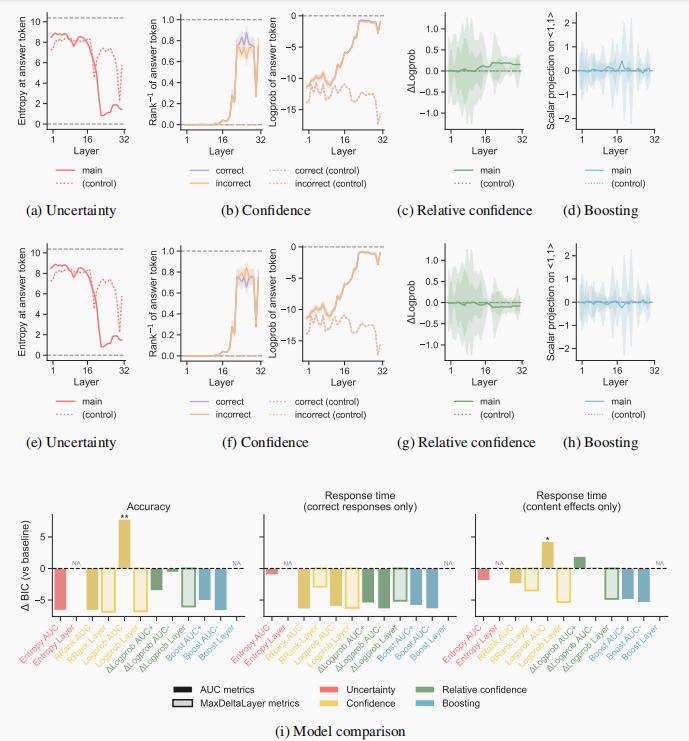
图注:(三段论推理中的内容效应),Llama-2 7B模型。(a)-(d) 针对逻辑结果与先验信念一致的题目,基于模型各层计算的处理指标。(e)-(h) 针对引发“内容效应”的题目(即逻辑结果与先验信念不一致),基于模型各层计算的处理指标。(i) 各指标及数据子集与基线模型的BIC差异,数值越高越好。由于EntropyLayer和BoostLayer在所有题目中的数值相同,因此未进行比较。
再来点烧脑的。经典的三段论逻辑推理题:
“所有A是B,所有B是C,那么所有A是C吗?”
人类本来逻辑在线,但题目稍微掺点“常识偏见”,比如“所有有翅膀的动物会飞,所有会飞的动物能上天,所以所有有翅膀的动物都能上天吗?”大脑会直接被“常识”带偏。
AI也是。论文里发现:只要题目设计得足够“绕”,AI和人类一样,都在中间层“陷入迷雾”,先押宝在那个直觉答案上,过了几个“脑回路”,才慢慢拉回正轨。
04. “图片辨认”——AI和人类都在“雾里看花”
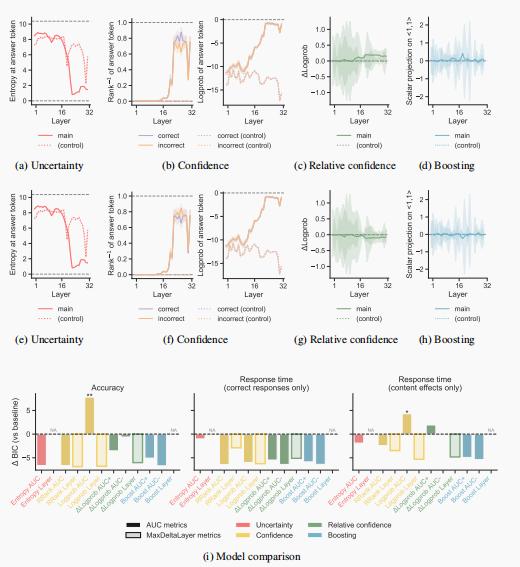
图注:OOD物体识别,ViT-Base模型。(a)-(b) 基于模型各层计算的处理指标。(c) 各指标分组与基线模型的BIC差异,数值越高越好。
视觉任务上也是同理。比如一张加了马赛克或奇怪滤镜的猫咪图片,问“这是啥?”你可能先说“狗?”,再揉揉眼睛,才发现是“猫”。
AI的Vision Transformer也是这样,刚开始层级信心分布很分散,也许更偏向“狗”,但随着层数推进,才慢慢聚焦到“猫”这个类别。
有没有发现?AI和人的“迷茫-清醒”过程竟然如此一致。
03 OMT:应该关注AI内部的“思考过程”
我们一直用AI做“黑箱”——输入-输出,像函数一样。但这篇论文告诉我们,也许更值得关注的,是AI内部的“思考过程”。
AI在遇到难题时,真的会“走弯路”,和人一样“卡壳”;不同的任务,不同的模型规模,AI的“思考路径”也会变化;这种“动态过程”不是专为模仿人类设计,而是AI自然训练出来、为了完成任务自己学会的“捷径”;
这意味着,也许我们能用AI,去发现哪些刺激、哪些设计会让人类更难处理,甚至反向指导人类实验设计。
输出只是终点,过程才是灵魂。
原标题:《哈佛新论文揭示 Transformer 模型与人脑“同步纠结”全过程!AI也会犹豫、反悔?》
阅读原文