程序员自制开源AI评分工具, 衡量大模型“愚蠢程度”
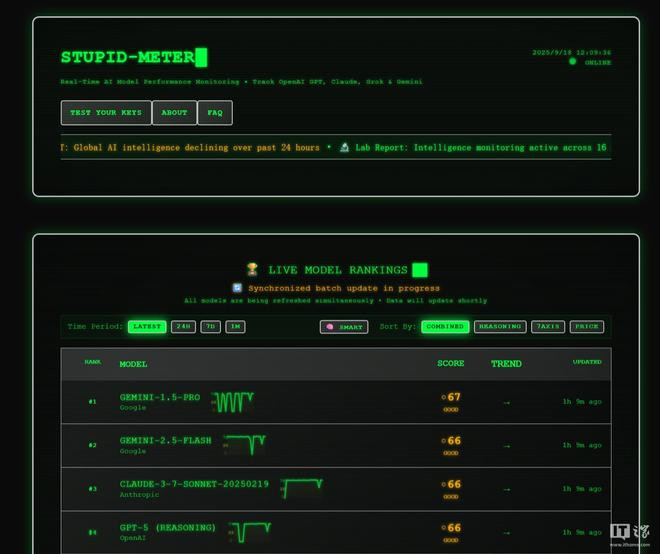
IT之家9月18日消息,程序员ionutvi今天发布了名为AIBenchmarkTool的AI评分工具,可衡量各大AI模型的“愚蠢程度”,帮助代码工作者选择最准确性最佳、更具性价比的AI工具。
ionutvi表示,他在使用ChatGPT、Grok、Claude等AI大模型时经常发现,有时候这些模型第一天工作正常,但第二天就会“降智”,做相同的任务时胡乱回答,有时候干脆拒绝回答相同问题,很多人认为这只是自己的问题,但这实际上官方有意降低了模型的性能,毕竟Anthropic官方就承认过这个问题。
因此他制作了这款AI评分工具,它可以自动在多款大模型运行140项编程、调试和优化任务,从准确性、拒绝回答率、回答时间、稳定性等方面衡量AI模型的“愚蠢程度”,并根据评分自动排名。
并且这名开发者还结合了各家的AI模型的价格综合评比,让用户知道每款模型的使用成本,有的AI模型看起来很便宜,但可能需要迭代10次才能得到能用的答案;而有的模型虽然价格比较高,但只要迭代两三次就能得到能用的版本,这种情况下稍贵的那款模型性价比就更高。